前言
splinter 是一个 python 的第三方库,主要用来进行 web 应用的自动化测试。有了它,你就可以从重复且无聊的 web 测试中解脱出来,像看电影一样看着浏览器自动完成大量的手工操作(比如说表单的录入等)。另一个用处就是在开发爬虫时模拟用户登录,简单的爬虫脚本肯定会被网站很快识别出来,要想骗过网络的验证,不妨用真正的浏览器去登录网站,区别在于,使用代码来操作浏览器而不是人工操作。
优点
说到 python 的自动化测试,一个比较有名的库就是 selenium,相较于 selenium,splinter 的优势就是小巧,方便,api 函数简洁明了(当然有优势,不然写这篇文章干嘛?),同时,缺点也比较突出,无法支持复杂的浏览器操作(如模拟移动端的 touch 事件),基本操作比如前进后退什么的没有任何问题。
安装
如果你使用 unix 系列的系统(土豪向的 Mac OS 或者技术向的 Linux),没什么好说的,一条命令搞定(可能要用到超级用户的权限):
pip install splinter
如果你和我一样使用大众向的 windows(或者说游戏向,好像暴露了什么),那么好多 python 的库使用 pip 命令来安装是会有问题的,关键在于依赖关系搞不定,别问我是怎么知道的。最朴实而有效的解决方法就是:在命令行窗口仔细察看报错内容,把需要的依赖一个个安装即可,推荐一个网站:PyPI - the Python Package Index,多找找不会有错。
还有就是安装浏览器的驱动,你喜欢哪个浏览器就下载对应的驱动(反正支持的浏览器也没几个),下载地址请移步到 官方文档 自行寻找。我使用的是 chrome。
几个要注意的点:
- 为了保证浏览器的正常运行,确保浏览器是正常安装的,何为正常安装?从官网下载的、未经修改并成功安装的。不是什么绿色版、修改版或者精简版等等。
- 严格保证驱动和浏览器的版本对应(32 位或者 64 位)
示例
举个例子(or 栗子?),来自官方文档(适当修改,适应国情及推广,哈哈):
# -*- coding: utf-8 -*-
from splinter import Browser
browser = Browser("chrome",user_agent="Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en)")
# Visit URL
url = "http://www.baidu.com"
browser.visit(url)
#Fill input box autoly
browser.find_by_name('word').fill(u' 春秋一语 ')
# Find and click the 'search' button
button = browser.find_by_id('index-bn')
# Interact with elements
button.click()
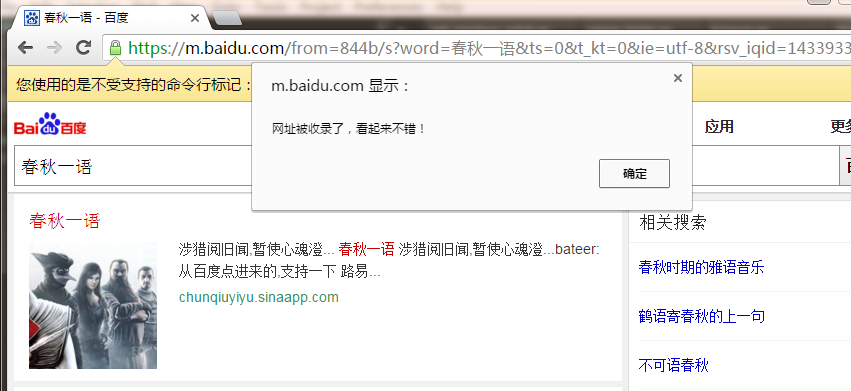
if browser.is_text_present('chunqiuyiyu.sinaapp.com'):
browser.execute_script("alert(' 网址被收录了,看起来不错!')")
else:
browser.execute_script("alert(' 还没发现网址,看来得针对引擎进行优化了!')")
麻雀虽小,五腑俱全。以上的代码涵盖了自动化测试中比较常用的几点:
- 驱动浏览器,并模拟 UserAgent
- 访问指定地址,并与其中的元素交互
- 模拟用户点击事件
- 检测页面内容并在页面执行 javascript 代码
特别注意**如果页面是动态生成的,那么使用审查元素得到的有些 DOM 元素是无法用 splinter 的选择器得到的,选择器中使用的 id 等只能是页面源码中本来就有的 **。
最后是结果图,有图有真相: